KatScript grammar, parser and generator
Source code: script
KatScript is an application-specific, declarative language used to build Finesse
models as an alternative interface to the Python API. The KatScript parser converts
KatScript from text files or the user’s shell into Finesse objects like models,
components and detectors. The KatScript generator does the opposite, taking a
Model and unparsing it back to KatScript.
Collections of tokens within KatScript represent elements such as mirror,
detectors such as pd, functions such as modes, analyses
such as xaxis, or comments and whitespace. Commands themselves may also
contain expressions, and expressions may contain symbols. The parser has to handle all
of these types of syntax.
Parsing KatScript is more complicated than many other typical small application-specific languages due to the nature of the script and the way in which it is typically used. KatScript is a declarative language, meaning that the order in which commands are defined should not influence the results; yet, because it has to create objects in Python - an imperative language - the parser must figure out the correct order in which to create commands and expressions that might rely on those defined elsewhere. Another issue to handle arises from the requirement to be able to regenerate KatScript from a parsed model in a similar form to the original script that built the model. This need arises from the way that Finesse is typically used when building “base” scripts to represent gravitational wave detectors. The process of constructing such scripts involves optimising particular aspects of the script sequentially, where the outputs from analyses are used to update the script before another aspect is optimised. The final script is then the form that is shared with others who can then use the optimised script to study a particular behaviour of the interferometer at the operating point.
This page describes the formal KatScript grammar, and how the parsing and unparsing toolchains work on a high level.
Note
While the process of converting some script into machine code is typically called
“parsing”, parsing is strictly just one part of the toolchain. As is typical, the
Finesse “parser” system is actually made up of a “tokeniser”, a “parser” and a
“compiler”. Similarly, “unparsing” collectively refers to the process of converting
a Model to KatScript, containing an “uncompiler” (itself containing an
“unbuilder” and “unfiller”), an “unparser”, and an “untokenizer”.
Grammar
Source code: script/parser.py
KatScript is a declarative grammar supporting statements and arguments. The following
sections contain a close approximation of the grammar rules in EBNF notation. When run, the
parser starts at the start rule and recursively reduces tokens
until finished, backtracking if necessary.
Note
The declarations below are not an exact definition of KatScript; the real grammar is more complicated due to the way in which whitespace and errors are handled. It is sufficient however for the purpose of outlining the key rules.
Script
Scripts contain zero or more script_line productions followed by
an ENDMARKER token.
start ::= (script_line+)?ENDMARKERscript_line ::= (statement)?NEWLINE
Statements
Statements are either element-like (space delimited) or function-like (comma delimited). Both have types but only elements have names.
statement ::=element|function
Elements
Element statements are space-delimited and may not span multiple lines. They take the
form myelement myname 1 2 3 d=4 e=5.
element ::=NAMEempty+NAME(empty+element_params)? element_params ::=element_value_listempty+element_key_value_list|element_value_list|element_key_value_listelement_value_list ::=positional_value(empty+element_value_list)? element_key_value_list ::=key_value(empty+element_key_value_list)?
Functions
Function statements are comma-delimited, enclosed in brackets and may span multiple
lines. They take the form myfunction(1, 2, 3, d=4, e=5).
function ::=NAME"("function_params? ")" function_params ::=function_value_listempty* ","empty*function_key_value_list(empty* ',')? |function_value_list(empty* ",")? |function_key_value_list(empty* ",")? function_value_list ::=positional_valueempty* (","empty*function_value_list)* function_key_value_list ::=key_valueempty* (","empty*function_key_value_list)?
Parameters
Parameters can be positional (simply a value) or keyword (a key, an equals sign, and a value).
positional_value ::=value!"=" value ::=expr|function|array|NONE|BOOLEAN|STRINGkey_value ::=NAME"="value
Expressions
Expressions can be unary (e.g. -1) or binary (e.g. 1+2). Standard operator
precedence is baked in to the
rules by the way in which they are separated and referenced by each other.
Note
In practice, there are additional aspects to these rules to match
empty productions between terms of the expressions if it is in
a context that allows it (e.g. a parenthesised expression or
function).
expr ::= (expr("+" | "-"))?expr1expr1 ::= (expr1("*" | "/" | "//"))?expr2expr2 ::= ("+" | "-")expr2|expr3expr3 ::=expr4("**"expr2)? expr4 ::= "("expr")" |function|array|NUMBER|NAME|REFERENCE
Arrays
Arrays are comma-delimited lists of values
or arrays contained within brackets ([...]).
Numerical arrays are created with type numpy.ndarray when a standard
array is contained within an expression.
array ::= "["empty*array_values?empty* "]" array_values ::=array_value(empty* ","empty*array_values)* (empty* ",")? array_value ::=expr|array|NONE|NUMBER|NAME|BOOLEAN|REFERENCE|STRING
Empty
Emptiness can be represented by whitespace, comments or newlines. Emptiness is sometimes
important (e.g. between parameters of an element), sometimes not
(e.g. between parameters of a function).
empty ::=WHITESPACE|COMMENT|NEWLINE
Tokens
Tokens are matched using regular expressions, as shown below. The matching is pretty
simple except for numbers. Numbers may be integer, float,
imaginary or scientific, and may contain SI prefices such as k. Scientific forms
cannot also use SI prefices. Number tokens are not tokenised with signs. Such unary
operations are matched as expressions and eventually converted into functions in a later
stage. Similarly, complex numbers are actually represented by two expressions (the real
and imaginary parts) and a binary operator (+ or -), built by the parser into
functions. The number matching regular expression is particularly huge; see
finesse.script.tokens.NUMBER for the full form.
Note
The ENDMARKER entry below is a meta token which has no
representation in string form. It is used by the tokeniser to indicate the end of
the current file.
NAME ::= [a-zA-Z_][a-zA-Z0-9_.]* NUMBER ::= (see text) STRING ::= '[^\n'\\]*(?:\\.[^\n'\\]*)*'|"[^\n"\\]*(?:\\.[^\n"\\]*)*" BOOLEAN ::= true|True|false|False NONE ::= none|None WHITESPACE ::= [ \f\t]+ COMMENT ::= #[^\r\n]* NEWLINE ::= \r?\n+ ENDMARKER ::= (see note) REFERENCE ::= [a-zA-Z_][a-zA-Z0-9_.]*
Parsing
Parsing starts with the tokeniser, which converts raw characters into particular token
types such as NAME, STRING,
NUMBER, COMMENT, etc.
Because it must be possible to regenerate KatScript including comments and whitespace from a parsed Finesse model, the parsing process produces a concrete syntax tree rather than an abstract syntax tree as is more typical. The tokeniser therefore does not ignore any token types, and the parser produces productions containing whitespace and comment tokens.
In the documentation below, tokens of a particular type are referred to using uppercase,
such as NUMBER to distinguish them from parsed productions such as
expr (expression).
Tokeniser
Source code: script/tokenizer.py
The available KatScript token types are defined in src/finesse/script/tokens.py
using regular expressions. Text may match multiple token types, but the order in which
they are defined in the overall regular expression that is built from the individual
token expressions in src/finesse/script/tokens.py determines the matching priority.
Parser
Source code: script/parser.py
The parser reads the token stream until exhausted and attempts to reduce them to productions, which are containers representing particular rules in KatScript grammar. The KatScript parser implementation is a so-called packrat parser, using recursive descent to perform unlimited lookahead, in contrast to e.g. LALR(1) parsers that can only look at the next character to decide which production to use to reduce the current tokens. This algorithm uses potentially unlimited memory but is guaranteed to run in linear time due to the use of caching. In practice memory use is limited by the input script size and KatScript grammar, which are both typically small with respect to available memory on modern computers. Packrat parsers also provide other advantages over LALR(1) such as the ability to handle left-recursive rules.
The first parser rule searches for all tokens followed by an
ENDMARKER. The ENDMARKER is a special token
yielded by the tokeniser to indicate the end of the file, and there should only be one,
which indicates the parsing should stop. Within the tokens it sees, the parser then
looks for lines (groups of tokens ending with a NEWLINE)
containing statement productions, which can themselves be either
element or function productions that accept
one or more arguments. These productions accept the same types of arguments but differ
in the way they require them to be delimited: in the case of
element arguments, the delimiters are spaces (on a single line),
whereas for function arguments the delimiters are commas (and whitespace and newlines
are optional).
Arguments can be numbers, null, booleans, expressions, references and strings. Expressions can be arbitrarily nested and take more care to parse in a way that obeys operator precedence; multiple rules are therefore required.
Containers
Some grammar rules in the parser have equivalent containers, which are objects that hold the tokens that represent the
relevant production. Rules without equivalent containers usually provide data to a
higher order rule that has a container. These containers are primarily used by the
compiler but also for error handling, so they inherit from TokenContainer
which defines some useful attributes and properties for figuring out where in the input
the production appears. There are also ArgumentContainer and
ExtraTokenContainer mixins which containers can inherit to conveniently add
support for additional types of data. The attributes these mixins define are also
recognised and supported by the compiler, so container-specific rules in the compiler
are mostly not needed.
Arrays
Arrays are sequences of numbers, expressions, strings, or other arrays. This data
structure is provided to allow such sequences to be passed to elements and commands.
There can be some special behaviour depending on the location in which the array
appears. Stand-alone array arguments are passed as lists, but arrays
embedded inside expressions are converted to ndarray so as to support
element-wise operations such as 2 * [1, 2]. This context-specific behaviour is
employed so that lists of strings can be passed to e.g. plot commands in KatScript
without having these converted to ndarray, which are most suited to
containing numbers.
Note that in order to support the default list type behaviour for arrays not
used in expressions, the array rule has to come before
expr in rules that can match both productions (otherwise all
arrays regardless of contents would be converted to ndarray).
Error handling
Source code: script/exceptions.py
Error handling in the parser is not “free”. Due to the nature of the recursive descent algorithm, if the syntax is incorrect the parser will back-track to the last successful production and try the next rule. If all available alternative rules are exhausted, only then would a syntax error normally be raised. This normally leads to unhelpful error messages, without any indication as to the syntax that actually caused the error, because the parser back-tracked all the way to the first rule. It is therefore also important to build a number of special rules into the grammar that match common error conditions, which can then trigger more useful error messages.
Handled errors usually raise a KatScriptError, which uses the provided error
item (a token or container) and the original script to figure out where to determine
where in the script the error(s) occurred. Depending on how Finesse is being run,
these error locations may be shown with markers or in a special colour. Here is an
example of an error message:
from finesse.script import parse
parse("laser l1 P=1 freq=1M") # "freq" is not a valid argument.
KatDirectiveBuildError: (use finesse.tb() to see the full traceback)
line 1: 'laser' got an unexpected keyword argument 'freq'
-->1: laser l1 P=1 freq=1M
^^^^
Syntax: l name P=1 f=0 phase=0 signals_only=false
Compiler
Source code: script/compiler.py
This section frequently shows the results of building KatScript into graphs, so we’ll define a convenience function to let us see them:
import matplotlib.pyplot as plt
from finesse.script.compiler import KatCompiler
from finesse.plotting import plot_graph
def plot_and_show(script, **kwargs):
"""Compile script and show the syntax graph."""
compiler = KatCompiler()
compiler.compile(script, **kwargs)
# Plot the graph, colouring nodes by their type.
plot_graph(
compiler.graph,
layout="planar",
node_labels=False, # Reduce clutter.
node_attrs=True,
edge_attrs=True,
attr_font_size=12,
edge_font_size=8,
ax=plt.figure(figsize=(12, 16)).gca(),
node_color_key=lambda node, data: data["type"],
bounding_ellipses=False,
graphviz=False,
)
The compiler’s job is to take the parsed productions and turn them into a model and elements containing the relevant parameter values
and references. There are three sub-steps to compilation: filling, resolving and
building. These all involve writing to or reading from a graph that gets constructed
to represent the KatScript’s syntax.
Filling
The filler matches different types of production yielded from the parsing step and
creates corresponding nodes in the graph. Productions that support arguments have these
arguments recursively filled as well, and edges of type ARGUMENT are drawn to each
from the owning node.
As mentioned in the introduction, a concrete syntax tree is constructed because
Finesse cannot ignore (and therefore must parse) whitespace, comments and other
meta-tokens so that it can still reconstruct something resembling the original kat
script later. In practice, the tokens stored in the container parsed from a particular
part of the KatScript are stored as node attributes. All containers have a primary
token, which is stored as the field token. Named containers (elements and functions)
also store a name_token field, and extra characters such as the = of a keyword
parameter are stored in extra_tokens.
After filling, the graph is strictly a tree because references between
parameters of different elements have not yet been resolved. Everything descends from
the ROOT node, which represents the model:
# Filled tree for a model containing a simple reference.
plot_and_show(
"""
l l1 P=(1/2)*l2.P
l l2 P=1
""",
resolve=False,
build=False,
)
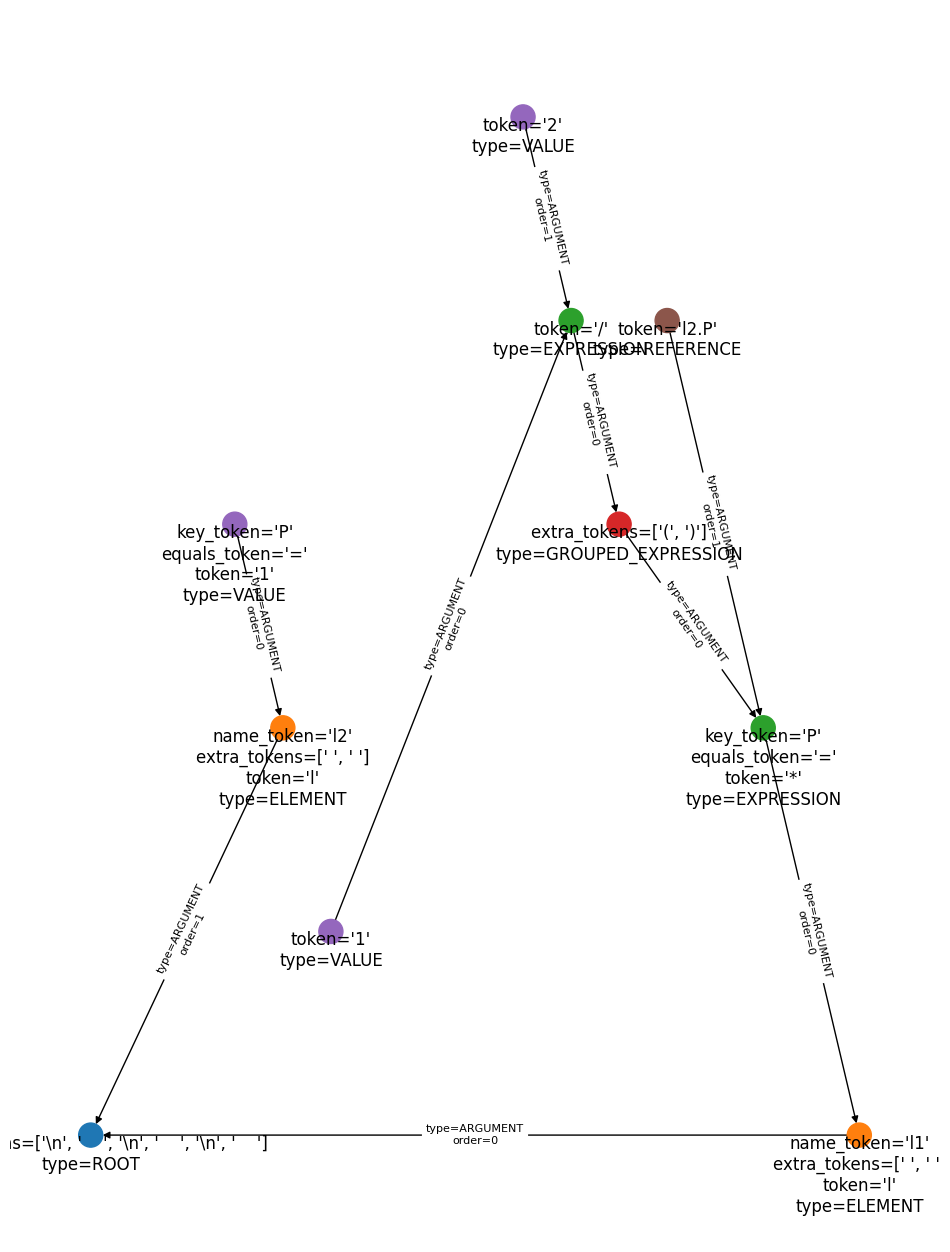
<Figure size 640x480 with 0 Axes>
Resolving
The resolver takes the graph and draws edges between dependencies created by references,
i.e. arguments containing tokens of type NAME or
REFERENCE. It also performs some sanity checks on the graph, such
as to check for invalid components, duplicate commands, and cycles between references
(i.e. that which would be created by e.g. m m1 R=m2.R T=0 and m m2 R=m1.R T=0).
After resolving, the graph looks something like this:
# Resolved graph for a model containing a simple reference.
plot_and_show(
"""
l l1 P=(1/2)*l2.P
l l2 P=1
""",
resolve=True,
build=False,
)
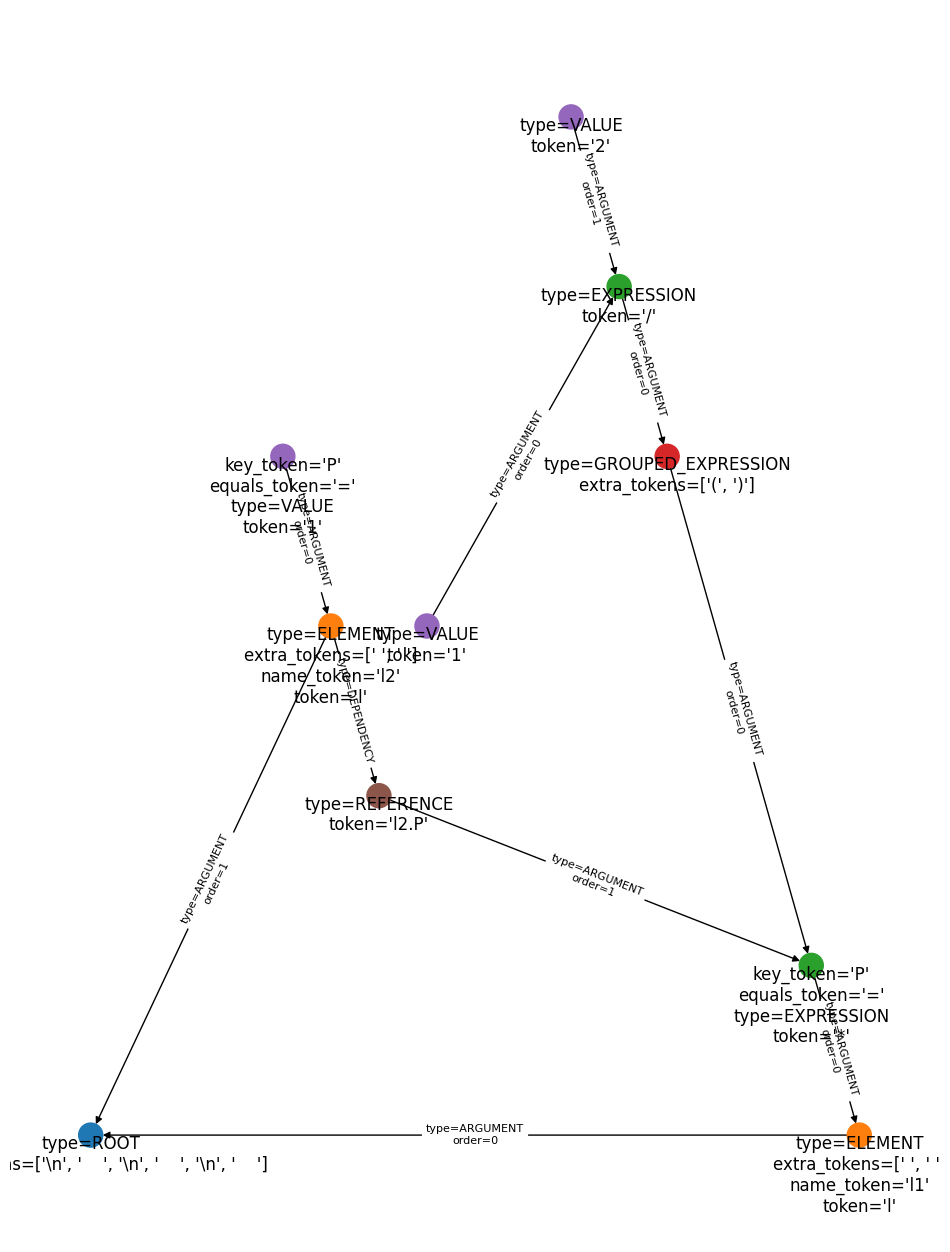
<Figure size 640x480 with 0 Axes>
Note that the l2.P node is now connected to l2 by a DEPENDENCY edge. The
l2.P node is the first statement (l l1 P=0.5*l2.P)’s first argument (P)’s
second argument. As a reference, this parameter depends on l2 existing by the time
it is being compiled, so an edge is drawn to the target to represen this dependency. We
don’t draw an edge to the target parameter node (P) itself because the target
parameter is created at the same time as its owning element anyway (this however doesn’t
give us a way to handle references between parameters of the same element, but we’ll get
to that in the build step).
The resolver also figures out the correct order in which the elements must be built
given the dependencies created by references. If you look closely at the ARGUMENT
edges from the root node, you will see that the order attribute has changed since
the filling step. This is because l1 depends on l2 (via its P=0.5*l2.P
argument) even though l1 was defined earlier in the script.
Building
The builder starts at the root of the resolved graph and recursively follows each
argument in order, building everything into relevant objects. It’s in this step that the
model is created (if one wasn’t provided), each element node is built into a relevant
ModelElement. Arguments are passed to the ModelElement constructors.
Statement-level functions behave similarly, with the arguments being passed to a
function instead of a model element.
The graph is used to determine whether a given expression can be eagerly evaluated.
Eager evaluation is possible for any expression node that represents a closed branch of
the graph, i.e. one without nested references. Such expressions are evaluated at compile
time, and only the resulting value is passed to the Python object or function. Compound
expressions containing references have only the closed sub-branches eagerly evaluated.
As an example, take the graph shown in the previous section. The expression for the
P parameter, (1/2)*l2.P, contains two top level clauses: (1/2) and l2.P.
The latter is a reference and must be left unevaluated at parse time, but the former can
be evaluated immediately. The builder therefore converts this expression to 0.5*l2.P
before it gets passed to Laser.__init__().
The final step in building is handling self-references, which are parameters that
reference another parameter in the same component. Such references create cycles in the
graph during the resolving step, but these are intentionally ignored at that time. These
references cannot be resolved in a single pass because element parameters are only
created when the element itself is created, via its __init__ method, and that method
requires initial values for the parameters. Instead, parameters that contain
self-references are built with an initial value set to a Resolving symbol,
which, if evaluated (e.g. by code running in an element’s __init__), will throw an
error. Once a component gets built, any parameters with Resolving symbols then
are fully resolved by calling the relevant build routine once again. This time, because
the target parameters now exist (because the element was since created), it is possible
to make real references to them using Finesse symbols.
The conversion between parsed, resolved arguments and Finesse objects is handled by
KatSpec, which contains a series of finesse.script.adapter.ItemAdapter instances
representing the available statements. This way, only the language constructs need to be
hard-coded into the parser stack and the available commands, elements and analyses can
be changed, e.g. to register a custom component.
Continuing with the example used so far, shown below is the result of the build step. Since this is also the last step in the parsing process, this is also what gets returned to the user.
from finesse.script.compiler import KatCompiler
compiler = KatCompiler()
model = compiler.compile(
"""
l l1 P=(1/2)*l2.P
l l2 P=1
"""
)
The Model contains the relevant items:
print(model.info())
<finesse.model.Model object at 0x796434768b90>
1 optical mode
==============
- [0 0]
2 components
============
- Laser('l2', signals_only=False, f=0.0, phase=0.0, P=1.0)
- Laser('l1', signals_only=False, f=0.0, phase=0.0, P=(0.5*l2.P))
0 detectors
===========
0 cavities
==========
0 locking loops
===============
Unparsing
Source code: script/generator.py
The job of the unparser is to transform a Finesse Model and other objects
into KatScript. Currently this is an experimental feature, though it is already quite
powerful - for example, combined with the legacy parser it is capable of converting
Finesse 2 style KatScript to that of Finesse 3.
The unparser can be used on models originally built with KatScript or via the Python API; it does not matter. The original KatScript form is currently not retained during model compilation, so unparsing does not retain the original form: script order may be different, comments are lost and whitespace is normalised. Future improvements to the unparser are planned to allow the original parsed form of a model to be retained as much as practical (see #200).
The unparser is a toolchain containing an uncompiler (itself containing an unbuilder and unfiller), an unparser, and an untokenizer. The majority of the computation takes place in the uncompiler stage, with unparsing and untokenizing relatively trivial operations. These are explained in the sections below.
Uncompiler
The uncompiler transforms a Model or other Finesse object into KatScript by
first building a KatGraph and then tokenising it. The graph filling is
performed by the unbuilder and the tokenising is performed by the unfiller.
Unbuilder
The graph is built using a functional programming dynamic dispatch paradigm, applying
polymorphic behaviour depending on type (using functools.singledispatch()). The
dispatcher is called recursively, with the code for each matched type extracting and
dispatching contained objects, adding nodes for each intermediate step, until types that
have direct KatToken analogues are reached. Edges are drawn connecting related
nodes, such as the name, parentheses, delimiters and parameters of functions.
For example, a model gets built by passing it to the dispatcher. The dispatcher matches
and runs the code for Model, which extracts its elements, commands and
analysis, further calling the dispatcher on each. In the case of the model’s elements,
the dispatcher matches and runs the code for ModelElement, which extracts,
among other things, the model parameters and once more passes
these to the dispatcher. Parameters containing terminal types such as numbers are again
dispatched, with the dispatcher this time matching code that creates a
KatNumberToken. The graph filled by this sequence is a tree (unlike the graph
built by the parser, where references create edges between branches), with each branch
(representing elements, commands and analyses and their constituents therein) ultimately
terminating with nodes corresponding to tokens.
Unfiller
The graph created by the unbuilder is converted into a series of production objects by using the type attribute defined for each node to
determine which production constructor to call. Connected nodes are themselves
recursively converted to appropriate productions.
The productions are added to a KatScript object. This is then passed to the
unparser.
Unparser
The unparser receives a KatScript object, loops through its productions,
extracts its tokens in order and calls the untokenizer.
Untokenizer
The untokenizer takes KatToken objects as input and converts them to their
corresponding KatScript string forms. In practice, the token’s raw value is simply
extracted and returned.